
Hasura is an Open Source licensed solution to implement GraphQL interfaces on a Postgres database. In my world, in which I am helping lots of product software companies this occupies a fairly interesting place, given that many architects rightfully choose Postgres for a variety of reasons, and also the adoption of GraphQL has lots of good (and less good) reasons.
For two of my clients we have used Hasura so far in our project , so that allows me to share my observations.
The long list
The obvious way to implement GraphQL is to build your own resolvers in whatever technology you use. We decided against it, nevertheless we looked at various product alternatives:
- https://www.graphile.org/postgraphile/
- https://www.prisma.io/
- https://aws.amazon.com/appsync/
- https://join-monster.readthedocs.io/en/latest/
- https://typeorm.io/
In the end, nothing looked as promising as Hasura, so we decided to give it a try. We started with Hasura 1.3.2 (Sep 23, 2020)
The good,
Starting with the most basic observation: it works.
Deployments are easy, developers can work with it, it’s stable and well performant.
The license is friendly, and so is the community and the (well funded) company behind it.
By accident, both projects shared some characteristics: both are multi-tenant, had no existing REST or other interfaces to convert or facade, and require serious business logic.
…the bad,
Serve side business logic in Hasura can be implemented in several ways.
CRUD logic and object relations are generated OOTB, and simple logic like user based authorization & access control, autofilling column values and limiting the number of results are supported out-of-the-box.
For augmenting the GraphQL interface with external APIs or additional databases automatic schema stitching is supported, named Remote Schemas.
Implementing regular server-side business logic with Hasura is done via a concept called Actions, this can be done either synchronous and asynchronous.
Our projects have (and many other larger ones will also have) a fair deal of synchronous business logic like validations, enrichments, workflow checks and transformations.
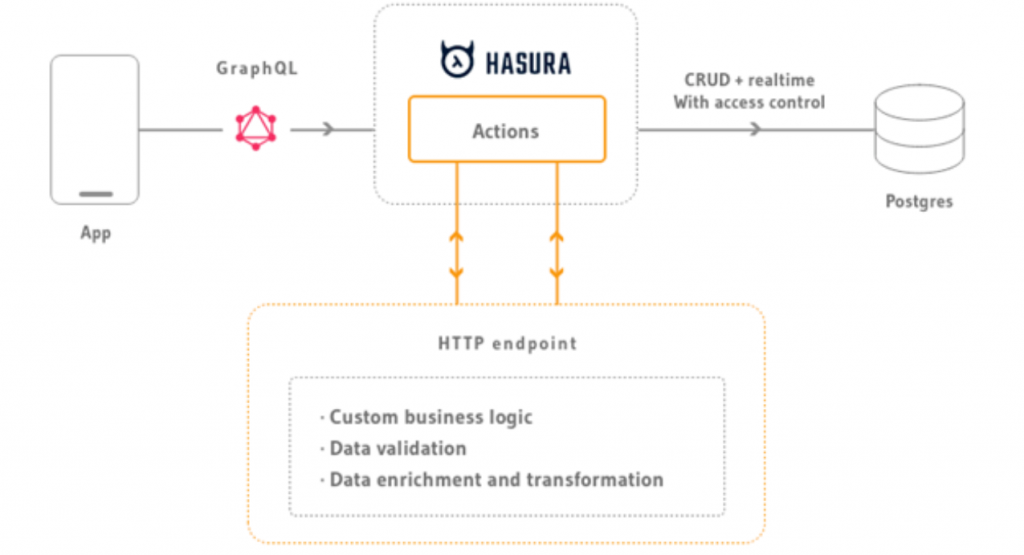
This Action concept gave us a lot of trouble. Adding or changing an action extends/changes the GraphQL interface, which is quite troublesome for business logic.
As an example, lets start with a table Test
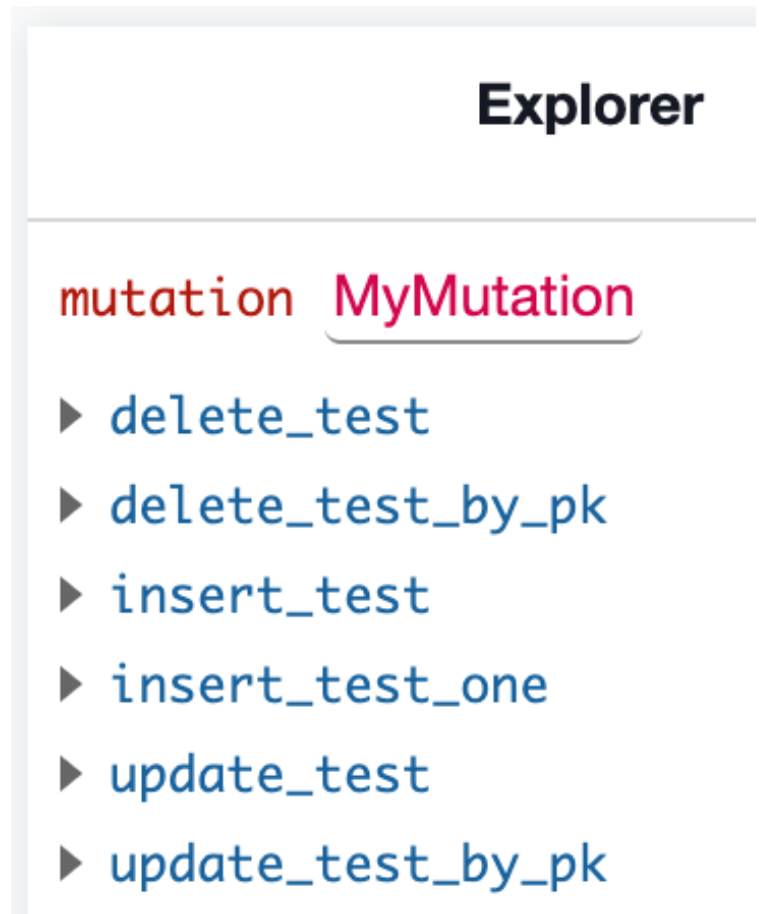
TestWhen we derive an Action LetsInsertIntoTest for the insert_test mutation:

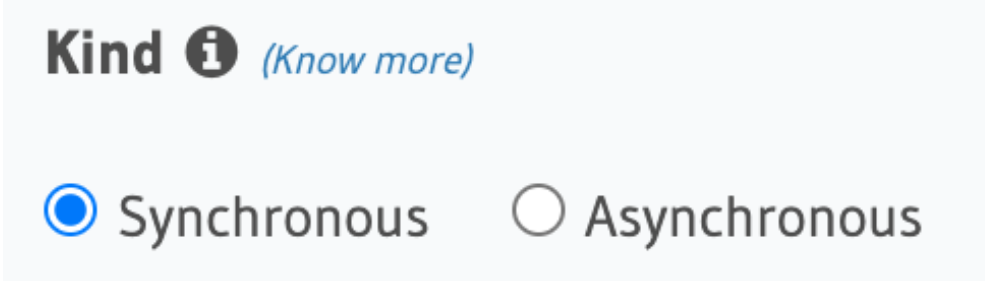
LetsInsertIntoTestDon’t forget to make the action execute synchronously when needed (for instance [age]>18 better be checked synchronously)
And we see the list of mutation interfaces has been extended with one that has business logic:
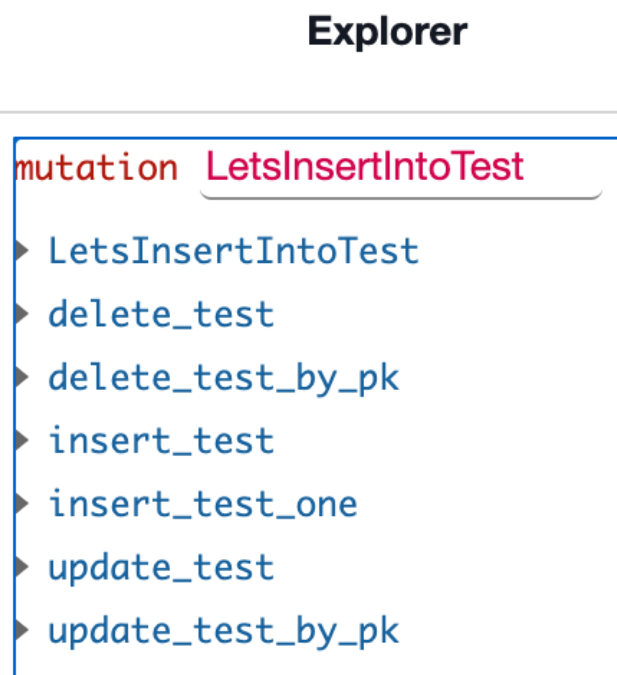
TestThis approach has several serious disadvantages that are really causing headache for my developers:
- Confusing: business logic is to be implemented in a web hook. This requires additional technology (we took NodeJS), and developers find it hard to understand whether database access must or must not be done from NodeJS.
Actions need to be implemented on multiple query roots, fi onupdate_testandupdate_test_by_pk. - Security: it’s not obvious how to get NodeJS code in the same transaction, session and security context as Hasura is running . Also the http connection that the web hook uses :
needs securing via certificates, a task that developers find hard to understand and automate for CI/CD.
Furthermore, it takes explicit action to disconnect the original graphQL interface that is not using the business logic, this is easy to forget.
Also business logic becomes quite visible in the interface.
- Decoupling: Business logic leads to API changes, and such API changes can impact any front end screen, either done or in progress, and require a full scan and retest of large pieces of front end
Actions need to be called explicitly, so front end needs to be aware of the business logic.
- API design: building great and well-documented APIs for public is made harder than needed, since the API definition is dependent on the data structure and the individual developer implementing the business logic.
- Cooperation: Several people working on the same business logic gave quite some dependency and communication troubles
…and the ugly.
As with any framework, there are pros and cons. Hasura is a fine working and well supported and documented framework, and beyond that we leave it to Hasura marketing to tell you how great it is.
The cons are worth mentioning here, since these are the lessons learned of two real projects with Hasura:
- Haskell treats ARM as a second tier architecture, so there is no decent support for Hasura on Raspberry Pi Kubernetes clusters or Apple M1.
- Hardened production dockers are not available. But hey, if you can’t harden your environments yourself, don’t take it in production.
- Hasura CLI is not running in docker, but requires a OS-level install
- Hasura is GraphQL only. Is this a pro or a cons? Anyway, please realise file upload, webcaching, transaction support, error handling and so on are not as simply generated as other parts of your API.
- CI/CD lifecycle support via Hasura Migrations isn’t the easiest, and Squash took us some deep thinking to get it right.
- Documenting the API is separate task, and is not in any way hindered or supported by Hasura.
- The embedded multi tentant security model either works or does not work for you. Don’t thing of Spring Security-like power.
- There is no versioning support on the GraphQL interface
- Subscriptions require web sockets, and are simple polling queries in Hasura.
- DDOS prevention is a headache as usual, attacks on complex joins etc are a user concern. Query performance is easy to detect, but hard to optimise.
- Postgres
Publicschema is used
Concluding
Hasura is a fine working, decent documented and well supported approach to prevent spending endless hours on building your own GraphQL resolvers.
It is good to see some technology that makes things bit simpler for developers in stead of more difficult, but projects still require a senior architect and skilled front-end & back-end developers to build a public facing commercial web application.
No way you need less people with Hasura. But you need less time. And that’s a step forward. For a 1.3.2 version of a new framework, thats not bad at all.